
剖析 Ruby 中的线程和全局锁


友好速搭的后端业务系统,主要基于Ruby构建,此外,我们还使用Node、Golang等技术。相比Node和Golang,Ruby的优势,在于开发效率更高,友好速搭能保持两周更新速度,Ruby功不可没。不过,作为解释型语言,Ruby劣势的历史更悠久,主要在于多线程、内存管理、性能等。
在Ruby1.9之前,Ruby的线程是在用户空间实现,只依赖一个系统内核线程,多线程无法跨CPU核心执行:
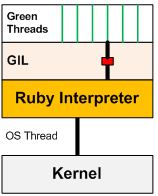
通过多个Ruby进程执行代码,既可以充分使用CPU核心,又不会有线程安全问题。所以在Ruby社区中,基于进程运行的相关产品,出现的更早。比如曾经Github推崇的Unicorn和Resque。
友好速搭最初上线时,也是用Unicorn+Resque组合,但在实际运行后,发现两个难题:
1.一个进程处理一个请求
一个进程只能处理一个请求,一旦请求处理时发生阻塞,会导致整个进程阻塞,无法处理其它请求。
2.内存消耗大
Unicorn和Resque以fork进程方式,来处理更多请求和任务,导致内存占用上涨速度很快。
如果提供一台高配置主机,上面的两个问题影响不大,但在云时代,使用低配主机集群,性价比更高。在尝试各种配置优化,无法解决上面的问题后,只好考虑通过线程解决。
Ruby自从1.9版本,就开始使用内核线程:
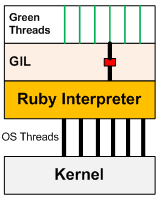
基于多线程,可以很好的解决进程中遇到的问题:
一个线程处理一个请求
一个进程可处理多个请求,并且某个请求处理发生特定类型(下文说明)的阻塞时,不会影响其它线程中的请求处理。内存占用少
所有线程共享内存,避免内存占用快速上升。
但由于线程本身通常很难把控,所以软件领域才有个古老的笑话:
从前,有个程序员遇到了一个问题。他想,没事,用线程就好。现在,他有两个问题了。
不过,Ruby社区中线程相关产品,已完善成熟,大幅降低了线程使用门槛。比如Heroku推荐使用的Puma用于替代Unicorn,以及替代Resque的Sidekiq。此外,Ruby中主流的Web开发框架,也都确保了自身的线程安全。那么剩下的,就是写出线程安全的Ruby代码。下面就剖析下Ruby的线程和全局锁。
Ruby中的GIL(也叫GVL),这个全局锁在进程中唯一,Ruby中的线程必须获得这个锁,才能执行。也就是说,虽然线程可以跨CPU核心执行,但一个Ruby进程中,同一时刻,只会有一个执行线程。

另外一方面,GIL并不能确保Ruby代码的线程安全,而是用来保护Ruby中,那些用C实现的函数线程安全。
下面基于代码来分析下:
以下Ruby代码,未做特别说明,默认是CRuby,v1.9以上版本,运行在Linux下。由于在Windows下,Ruby的线程实现与Linux不一样,下文不做分析。
array = []
1000.times.map do
Thread.new do
if array.size < 50
sleep(0.001)
array << nil
end
end
end.each(&:join)
puts array.size
ruby ruby_thread.rb
上面的代码,目标是向数组中,添加50个元素。但每次执行时,返回的结果可能都不一样。
当把上面的sleep(0.001),改为sleep(0.1)时,每次执行返回都是1000。
可以查看Ruby源码中的thread_start_func_2函数,在线程创建时,通过gvl_acquire获取GIL,线程执行完成,调用gvl_release释放GIL。
如果一个线程,在生命周期中,只有一次GIL的获取和释放,线程内的代码执行期间,独占进程中唯一的GIL。那不会发生线程安全问题,使用多线程,也没有任何优势。
上面的代码执行结果显示出,确实发生了线程冲突。也就是线程在代码执行过程中,发生了上下文切换(context switch)。那Ruby如何调度线程切换执行,是问题关键。
通过获取GIL函数gvl_acquire_common,可以发现,当线程获取GIL后,如果它是创建的第一个线程,就会调用rb_thread_wakeup_timer_thread_low激活一个计时器线程:
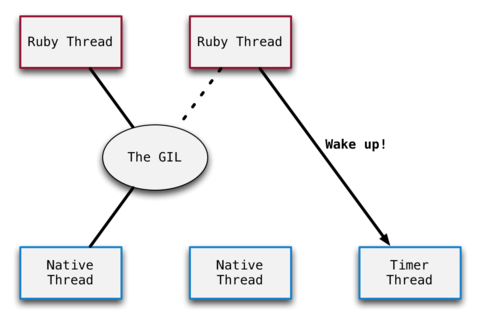
这个计时器线程,就是Ruby实现线程调度关键。它被唤醒后,每100毫秒就会在当前拥有GIL的线程上,设置中断标志位RUBY_VM_SET_TIMER_INTERRUPT。
在Ruby的函数调用源码vm_eval.c中,在执行完C代码,返回结果前,会检测中断标志位。如果线程的中断标志位被设置,那在返回结果前,就会停止当前线程的代码执行,释放GIL并调用sched_yield,来通知操作系统执行其它线程。之后,被中断的线程,只能等待后续调度。
也就是说,GIL的存在,可以保护好Ruby中的那些由C实现的函数,因为在中断时,执行完C函数体,才会通知操作系统切换执行线程。例如上面代码中数组的<<函数是线程安全的。如果在没有GIL的多线程环境中,针对数组的<<操作本身就不安全。
例如,使用Rubinius和Ruby,分别执行以下代码:
array = []
1000.times.map do
Thread.new do
array << nil
end
end.each(&:join)
puts array.size
rbx ruby_thread.rb
ruby ruby_thead.rb
Rubinius的执行结果,每次都会不一样,而Ruby的执行结果总是1000。
在开头的代码中,每一句执行完,都可能发生上下文切换:
| Ruby执行 | 线程标识 |
|---|---|
if array.size < 50 |
thread_1 |
if array.size < 50 |
thread_2 |
sleep(0.001) |
thread_1 |
sleep(0.001) |
thread_2 |
array << nil |
thread_1 |
array << nil |
thread_2 |
| ... | ... |
而当sleep(0.1)时,由于Ruby线程调度的间隔就是100毫秒,导致1000个线程在sleep期间,都会发生上下文切换,每个线程都能通过array.size检测,向array添加元素。
到这里,大家应该能明白,在文章开始时,提到线程的阻塞时,为何要加上特定类型。不同阻塞类型的区分,主要在GIL的释放时机。
在Ruby的多线程中,如果当前执行线程阻塞,并且发生在Ruby的C函数中,例如IO.read,那要等到C函数执行完成,才会释放GIL,接着其它线程才可以执行。当GIL是在函数执行前释放,那在函数执行期间,执行线程可以随时切换,这时才能发挥多线程优势。
如果在Ruby代码中,一旦开始执行C代码,就导致上下文切换失效,那多线程相比多进程,并没优势。但好在,在Ruby中用C实现的函数里,耗时的函数已经很少,而基于C拓展的库,Ruby社区也都形成默契,会在函数执行前释放GIL,执行完耗时代码后,再重新获取GIL,以避免影响上下文切换,例如ruby-pg中的实现。

